
Is Generative AI the New Dot-Com Bubble?
Or if not, is it the new oil?


You’re no doubt sick of reading about artificial intelligence as every tech writer, product manager and CEO seems ever insistent that the latest generative AI model is going to change the world. It’s estimated that there are 70,717 AI startups worldwide, including 214 unicorns (privately owned startups valued at over US$1 billion). Forecasts say that the AI market is expected to reach $184 billion by the end of 2024 and could reach $826.70 billion by 2030. But is it realistic for this brand new market to sustain nearly 30% growth, year on year, for five years?
As someone who is frequently asked about the role of AI and its future, I've started to question whether we might be witnessing the inflation of a dot-com-like bubble, poised to burst. While the advancements in LLMs are undeniably impressive, it's essential to scrutinise the sustainability and long-term impact of these technologies.
Spectacular, Yet Incremental Advances
The performance of LLMs, such as OpenAI's GPT series, is nothing short of remarkable. These models can generate coherent text, translate languages, and even write code. But how do they work? Have we created artificial intelligence or just an auto-correct on steroids?
My concern is that much of the science behind LLMs reminds me of my time as a Computer Science student. I won’t dive into the details here, but Sean Trott and Timothy Lee wrote a great primer that I can highly recommend for the casual reader. As the pair describe, much of the research around LLMs has been around for decades. The fundamental change in recent generative aI news is mostly a story of scale.

The magnitude of modern generative AI models is simply breathtaking. In February 2019, OpenAI released the GPT-2 model that used 1.5 billion parameters. In June 2020, GPT-3 followed with a staggering 175 billion parameters and training data exceeding 500 billion words. If leaked news is to be believed, GPT-4 has more than a trillion parameters and was trained on roughly 10 trillion words.
“Any sufficiently advanced technology is indistinguishable from magic.” - Arthur C. Clarke
Unsurprisingly, it is developments in GPU technology that has made much of the advancements in artificial intelligence possible. With the ability to process ever increasing libraries of training data, GenAI is able to amaze users with human-like responses to almost any query.
But how long can we continue to feed the machine?
The Scarcity of Quality Data
High-quality training data is a critical component for LLMs, yet it is surprisingly scarce. A recent study indicates only 50% of internet traffic comes from humans, that 32% comes from "bad" bots, and 18% from "good" bots. This bot-generated content risks contaminating the training datasets, leading to AI models that amplify misinformation and low-quality data. As a result, there have been several instances where companies have been accused of using unethical or illegal means to harvest data for the purpose of training AI models.

OpenAI themselves have found themselves in deepening legal hot water, with legal proceedings raised by a number of news outlets over the harvesting of copyright material to train GPT models. Indeed, in a submission to the House of Lords communications and digital select committee, OpenAI said it would be impossible to train today’s leading AI models without using copyright materials.
The problem is such that Adobe is reportedly buying video content for $3 per minute to help build it’s AI models.
Companies that historically relied on advertising are now securing lucrative deals to sell customer data to those training AI models. In February 2024, Reddit reportedly made a $60 million deal with Google, followed by Reddit stocks surging 14% in May after similar news of a deal with OpenAI.
As data becomes increasingly valuable, organisations are revising their privacy policies to monetise their information assets. It’s no surprise then that end users are increasingly sensitive to how their data might be used when consuming AI and other SaaS offerings - beautifully highlighted by the recent Twitter thunderstorm after Adobe made some questionable changes to its T&Cs.
Financial Viability of AI Investments
Research indicates that as LLMs grow, the amount of additional data required to achieve marginal improvements increases significantly. This trend suggests that LLMs will eventually reach a plateau, where the cost and effort to enhance performance will outweigh the benefits. This scenario challenges the prevailing belief that AI will continuously improve until it reaches near-perfect accuracy.

Dario Amodei, cofounder of Anthropic says the AI models currently in development will cost $1bn to train, and the 2025 and 2026 models might be $5bn or $10bn!
Other economic considerations further complicate the AI narrative. Sequoia Capital estimates that the AI industry has invested $50 billion to generate a mere $3 billion in revenue. This stark imbalance underscores the financial risks associated with AI development. If AI advancements do not transcend beyond being sophisticated assistants, the financial implications could be dire.
I was recently talking with some smart people in the medical sciences world, where machine learning has long proven its tremendous abilities at assisting experts in finding anomalies in health data. When it comes to generative AI though, they have a similar challenge to everyone else … so called “hallucinations”.
Where machine learning models work on a principle of probabilities, generative AI will happily answer any query with the blind, unshakeable confidence of a teenager.
The question remains whether generative AI will ever attain a level of reliability where its output can be entirely trusted, allowing humans to truly delegate tasks. Until then, it remains just a somewhat helpful virtual assistant that can help.
And, assuming we can find and afford the data necessary to train such a model, what else might we need to consider?
The Ecological Cost of AI
The media has begun to shed light on the substantial ecological footprint of training LLMs, paralleling the eventual scrutiny faced by crypto-mining.
Researchers estimated that creating GPT-3 consumed 1,287 megawatt hours of electricity - the equivalent annual consumption of over 350 UK homes - and was responsible for over 550 tons of carbon dioxide.
Unfortunately, the story doesn’t get much better after the model is trained. Some sources claim that ChatGPT consumes around 60 times more energy per query than a conventional Google search.
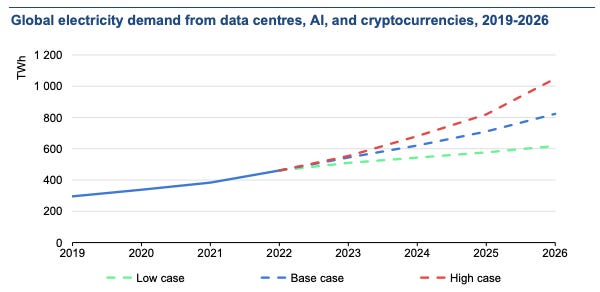
According to the International Energy Agency’s Electricity 2024 report, data centres, cryptocurrencies, and artificial intelligence consumed about 460TWh of electricity worldwide in 2022, accounting for almost 2% of total global electricity demand and 2.5% to 3.7% of global emissions - surpassing the aviation industry’s 2.4%.
Conclusion
Much like the dot-com bubble of past, it’s undeniable that generative AI and Large Language Models will have an immense impact on how we interact with computers, but it feels unrealistic that the everything needs or will benefit from AI.
For those use cases that can truly benefit from the technology, the potential environmental costs, data scarcity, diminishing returns, and economic viability all pose significant challenges that must be reviewed carefully.
My hope is that we can navigate these new challenges more adeptly than the early 2000’s.